
Chakraborty 2021 Reproduction and Modification
We implemented reproduction and reanalysis study on “Social Inequities in the Distribution of COVID-19: An Intra-Categorical Analysis of People with Disabilities in the U.S.” by Jayajit Chakraborty. I acquired insights into constructing the workflow of scientific research and learned how to design a reproduction study that mirrors this workflow. Throughout this process, I realized that certain steps in the original study couldn’t be replicated due to various factors, such as the unavailability of specific tools, challenges in replicating analyses within the same computational environment, and the absence of information regarding arbitrary decisions made during the study. Moreover, there were instances where we had to infer the author’s actions and parameter choices based on intermittent results during the study. Some aspects of the reproduction involved experimenting with different methods or tools, resulting in variations from the original study. For instance, we initially utilized SpatialEpi for Kulldorff spatial scan, which, due to its open-source nature, produced different clusters compared to the Kulldorff spatial scan in SaTScan, the tool used by the author. I believe these differences do not necessarily indicate errors but rather serve as reminders for us to delve deeper into understanding the distinct underlying mechanisms of the same tool in different software packages and determine which one is better suited for the study’s objectives.
My contribution to the study involved adjusting a default parameter of Kulldorff spatial scan in SpatialEpi to observe its impact on the resulting clusters. Some clusters generated under the default conditions appeared unreasonable, and reducing the pop.upper.bound parameter to a lower value noticeably improved cluster quality. Here are some of the comparison maps that I produced.
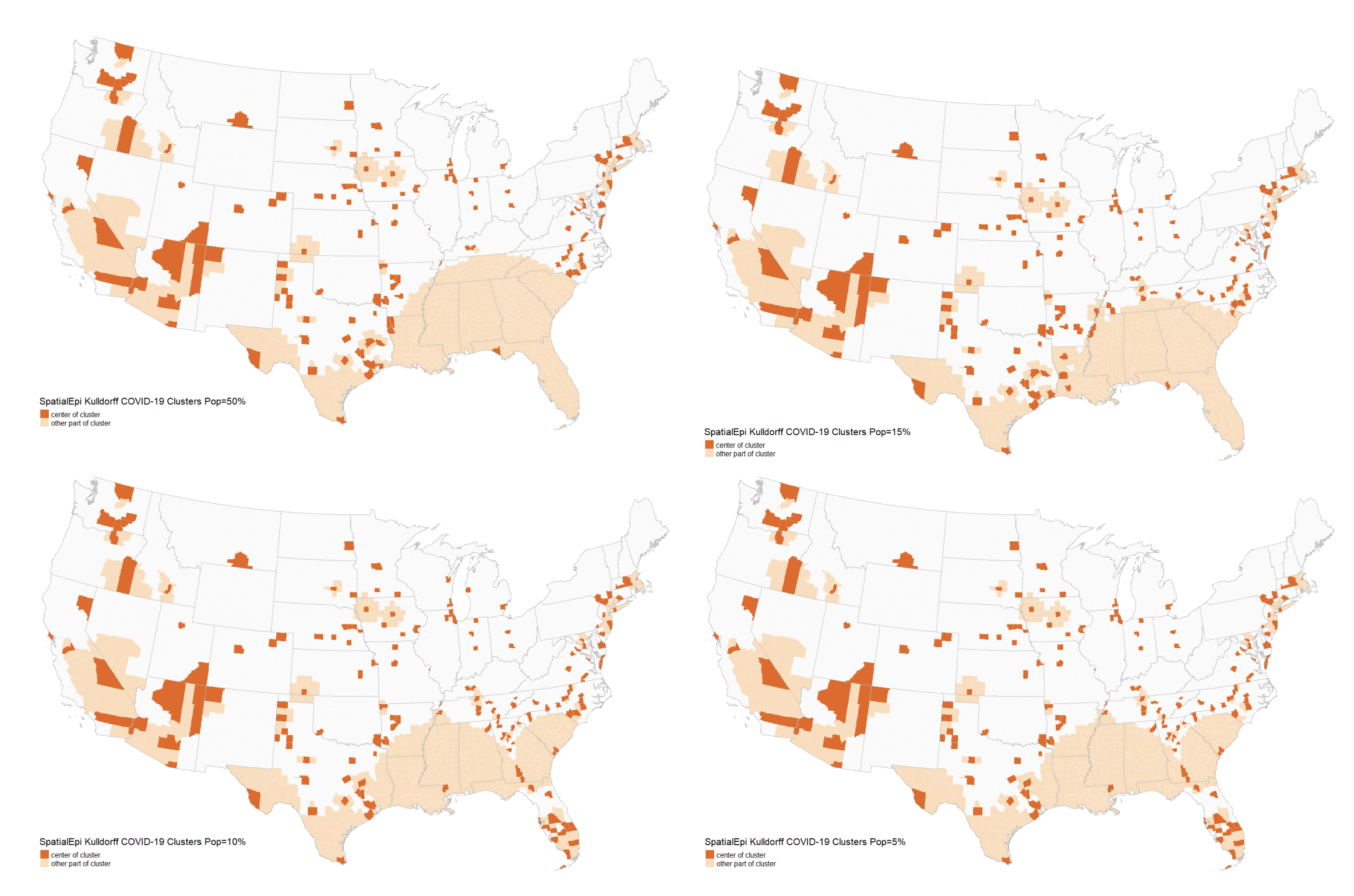
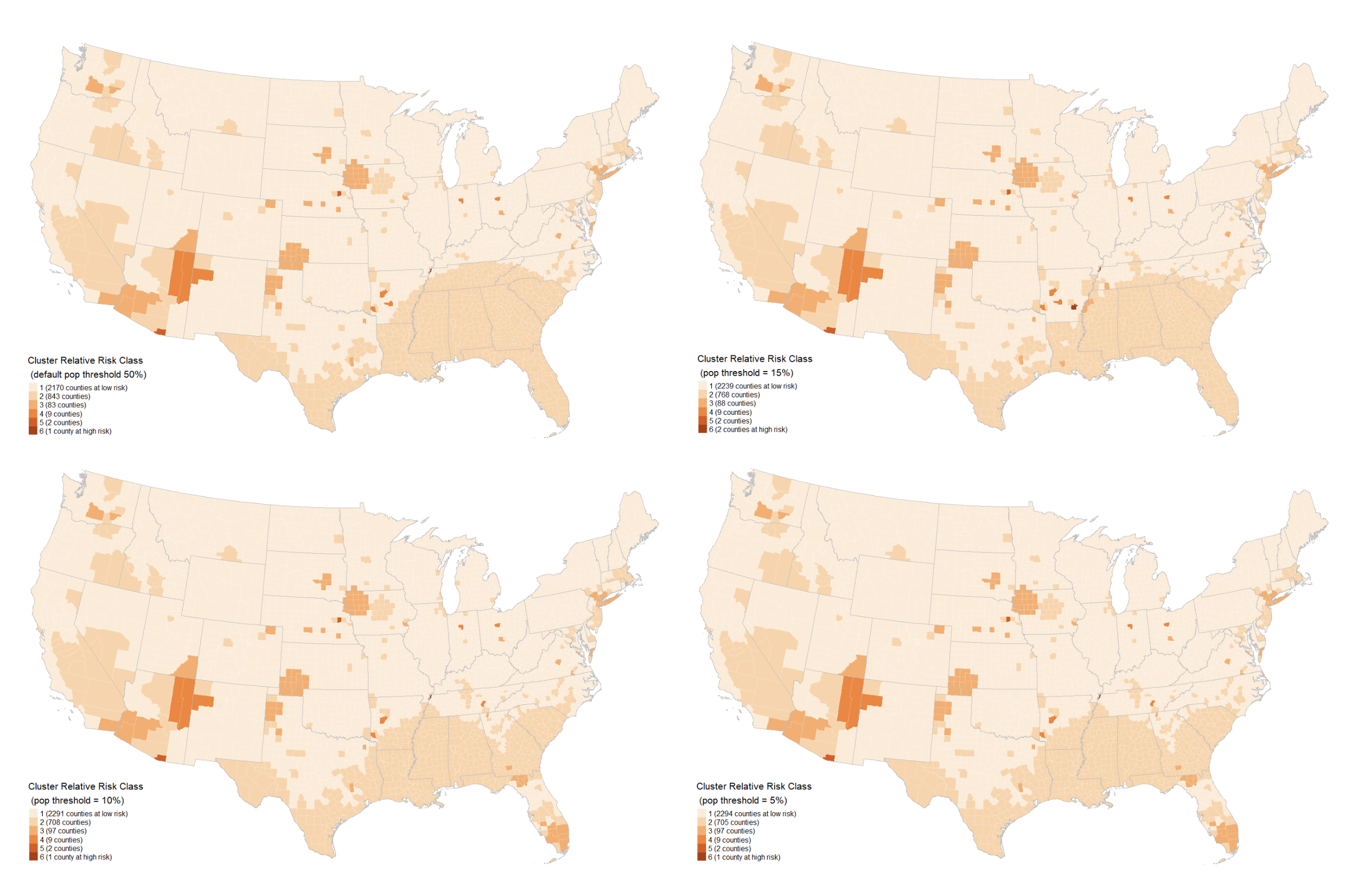
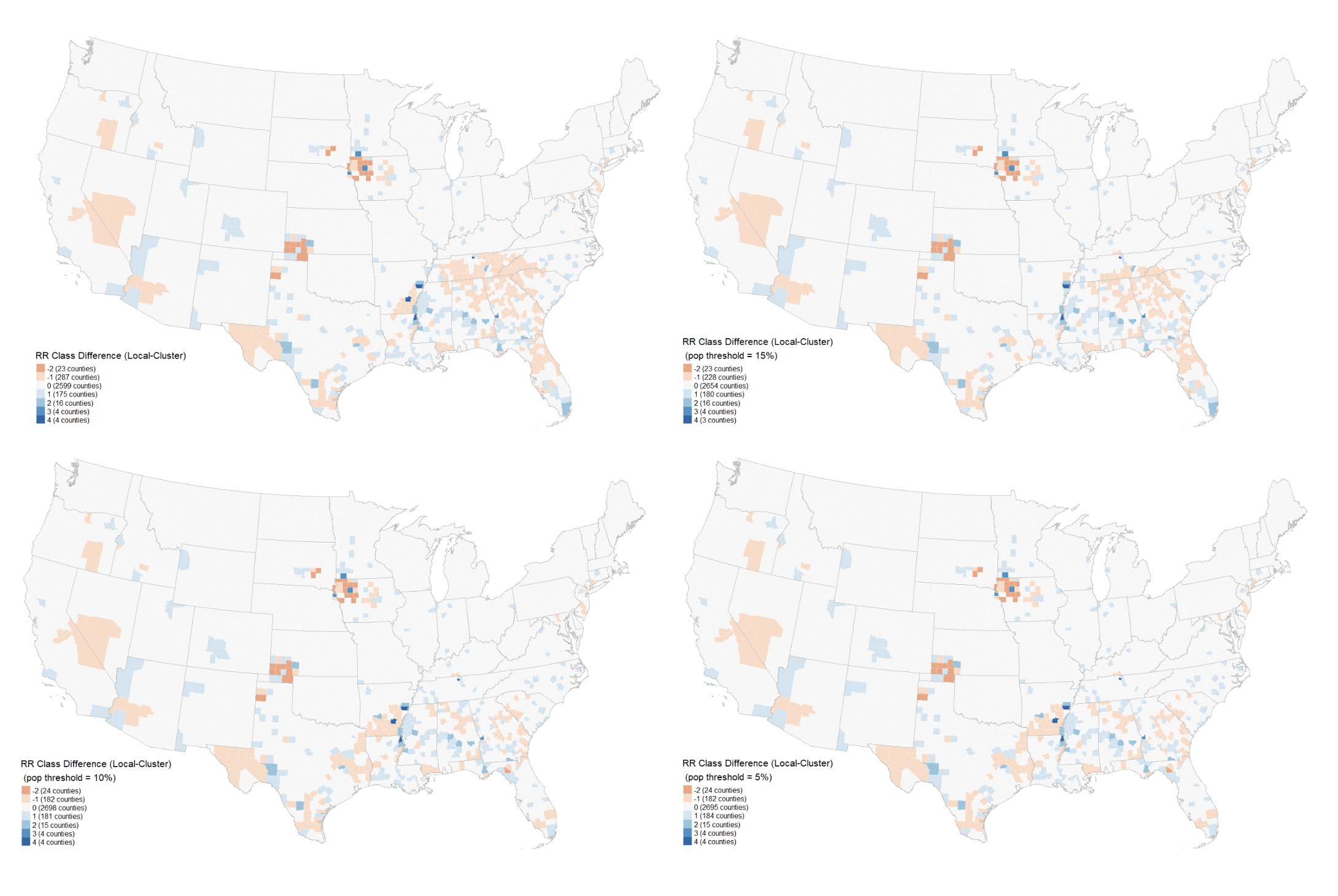
The reproduction process underscored the importance of providing readers with more intermediate results and justifications for specific decisions to facilitate future reproduction efforts. To test the resilience of demographic category coefficients, it may be plausible to follow the study using data generated from alternative deviation steps that differ from the original study. For example, we could use clusters generated by SpatialEpi as input for the five GEE models and assess whether the coefficients undergo significant changes due to this new set of clusters. Additionally, we might explore more complex shapes for COVID incidence clusters, moving beyond circles to create more realistic scenarios for GEE models.